本篇文章中,網路世界最重的協議 http,不只如上圖應用所示只有用戶端那有用到,現階段大部份很多 server 都還是會實用 http 去其它 server 取資料,所以一個系統中,最重要的應用層協議,咱們幾乎可能說是『 Http 』。
本篇文章分為以下幾個章節,事實上也就是所謂的 http 進化史 :
網路層的 http 優化事實上沒有啥重點,那就是 :
儘可能將 http 升級更高的版本
但是,為什麼要升級才是這一篇文章的重點。
在這篇文章正式開始一前,咱們有些前知識要來學習一下,不然下面會有很多東西看不太種。
首先 http 基本上可以說是網路世界的基礎,它當初建立出來的目的是為讓瀏覽器這個應用層的應用使用,然後它在傳輸資料時所使用的協議為『 TCP 』,所以當咱們要建立連線時會進行所謂的『 TCP 三次握手 』如下圖 1 所示 :
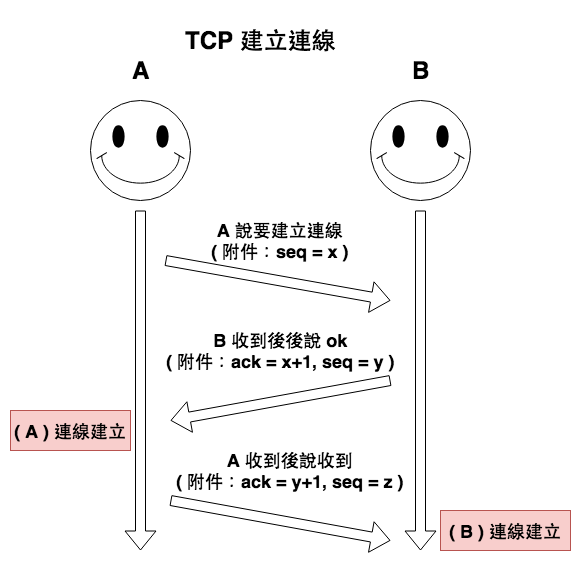
圖 1 : tcp 建立連線 ( 三次握手 )
然後有了這個連線以後,咱們就可以開始進行資料傳輸。
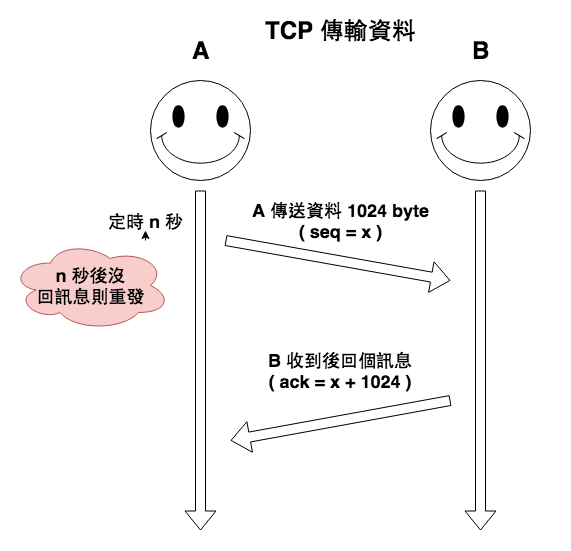
圖 2 : tcp 傳輸資料
最後斷線時就有所謂的四次揮手。
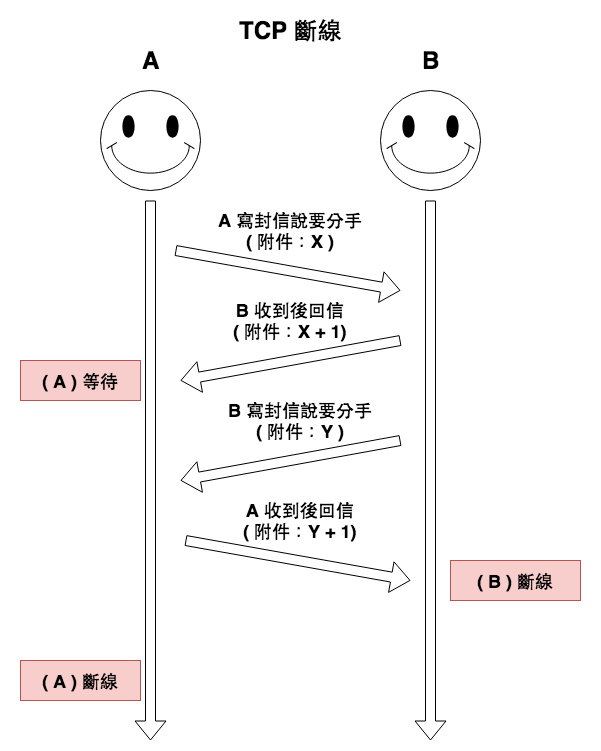
圖 3 : tcp 斷線 ( 四次揮手 )
~ 小備註 1 ~
如果不太熟細 tcp 的知識的友人,可以至筆者之前寫的這篇文章看看。
~ 小備註 2 ~
如果是連『網路協議』是什麼都不太能理解的友人,可以至筆者之前寫的這篇文章看看,希望可以幫到你。
首先咱們簡單的從最原始的 1.0 談一下,它的基本特點就是如下圖 4 所示,一個請求會需要執行連立連線、傳輸資料、斷線這三個步驟。而假設有 10 個請求,就要重複執行這 10 次。
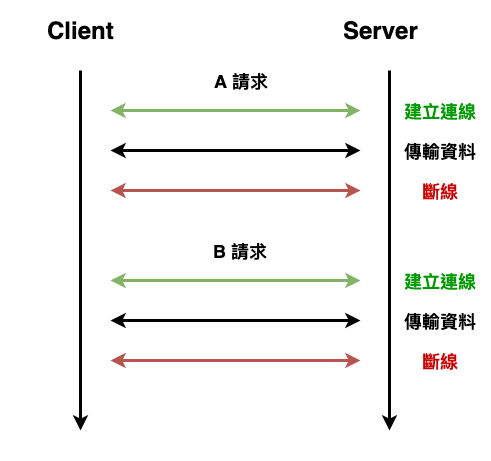
圖 4 : 沒有 keep-alive 的 http 請求流程
當然你想想,如果所有 http 請求都是這樣處理,那就代表每一張圖、每一個檔、每一個 html 都需要進行 tcp 三次握手建立連線與四次揮手關閉連線,這樣對發送方與接受方帶來的性能影響非常的巨大。
因為就誕生一個叫『 keep-alive 』的機制來復用 tcp 連線。
就是在 header 上加上這個標頭 :
Connection: Keep-Alive
MDN-WEB-Connection
MDN-WEB-Keep-Alive
那這樣在傳完資料以後,就不會自動關閉連線,而之後的請求也就同樣使用這連線就好,如下圖 5 所示。
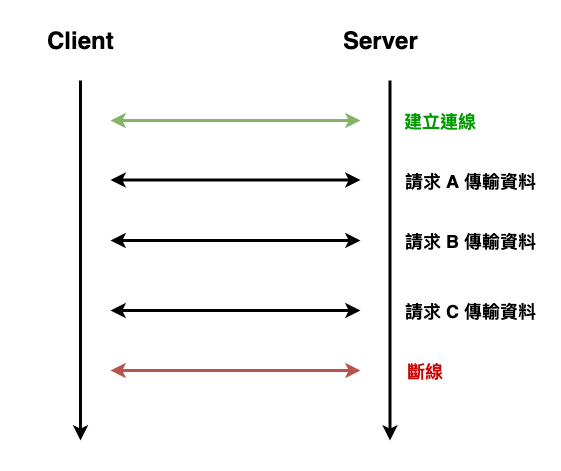
圖 5 : 加上 keep-alive 後的 http 請求
keep-alive 這個參數在 http 1.1 預設就是會幫你帶,也就是說在 1.1 預設是長連線,但不代表這個連線會永久存在,通常會有一個 keep-alive timeout 參數會設置一段時間沒有用後,就自動關閉。
keep-alive timeout 這個參數通常會是會在 web server 設置,例如 nginx 可以設定成如下。其中 75 秒是 nginx 的預設。
http {
keepalive_timeout 75s
keepalive_requests 100
}
而上述這些就是 http 1.1 的現況。接下來咱們來看看 http 1.1 這個我們最常用的協議,它還有那些問題 ?
如下圖 6 ,也就是一個請求需要等待回應以後,下一個請求才能發出去。
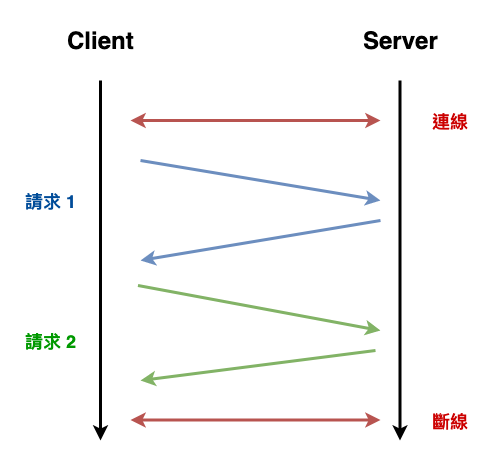
圖 6 : http 串行請求概念圖
然後咱們以回應時間的角度來看一下它的時間,如下 :
Request A : 2 sec
Request B : 1 sec
Request C : 3 sec
(這些秒數代表 server 所需花費處理時間)
第 0 秒時 : 發送 request GET A
第 2 秒時 : 收到 request A 回應,並且發出 request GET B
第 3 秒時 : 收到 request B 回應,並且發出 request GET C
第 6 秒時 : 收到 request C 回應
共 6 秒
為什麼呢 ? 為什麼會只能串行傳輸呢 ?
這點我真的不知道,我查了很多文章都只寫說 http 1.x 發送請求後,需要等到回應,才能在發下一個請求,就寫這樣,就算去看這個非常厚的文件,好像也沒看到寫為啥,目前也只能去慢慢的挖這份文件來找答案…… 目前覺得比較大的原因可能在於 tcp,但只是推測,目前沒看到任何文件有說 tcp 導致 http 只能串行傳。
rfc2616-Hypertext Transfer Protocol -- HTTP/1.1
可是為什麼我打開不少網站,然後開 chrome devtool networrk 看,有些請求是並行啊 ?
有幾種情況 :
這些情況下,那就有可能看到並行。順到說一下,如果不太清楚 http 緩存的東東,可以參考筆者的這一篇文章。
http 嘗試建立一些方法來進行比串行傳輸更有效率的方法。
而這方法所謂的 HTTP Pipeline
請求過程會變成如下圖 7 所示,就是將二個 http 請求打包成一組 tcp 資料發送,然後這時回應該就一次收二個 ( 依順序 )。
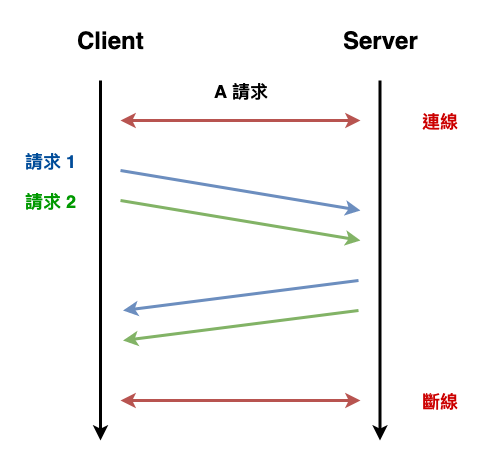
圖 7 : http pipeline 請求
下面這簡單的回應時間範例可以來讓我們更能理解 pipeline 的運行。
Request A : 2 sec
Request B : 1 sec
Request C : 3 sec
(這些秒數代表 server 所需花費時間)
第 0 秒時 : 發送 request GET A,B,C
第 1 秒時 : 等待
第 2 秒時 : 回應 request A,B (由於 B 排在 A 後面,所以即使 B 已經完成,但仍然還是要照順序回應)
第 3 秒時 : 回應 request C
共 3 秒
這樣的確可以增加性能,但是它有幾個問題。
由於有以上幾個問題,因此目前大部份的瀏覽器 http pipeline 功能預設都關閉。
比較詳細的原因可以參考這篇 stackoverflow 的回答。
~ 小知識 ~
tcp 也有所謂的 head-of-line blocking 喔。
由於上述所說 http 現階段只能串行傳輸,這也導致有些人會改使用另外開新 http 連線 ( 就是另開一個 tcp ) 來處理請求,但這時就有個問題會導致並行處理數上不去 :
瀏覽器對 domain 的 http 請求限制,以 chrome 的話它是 6 個限制。
由於無法使用 pipeline 且 domain 有限制 http 請求數,因此在 http 1.1 的世界中,開發者基本上有一個共同的準則 :
儘可能的減少 http 請求
對,只要能減少 http 請求,即時只能串行傳輸,那性能影響也可以壓到很小。所以後人發展了以下幾個奇技淫巧來儘可能的減少 http 請求 :
這是專門用來傳送圖片的,正常來說 http 只能傳送一張圖片,所以如果一個畫面有很多圖,那就要發送很多次請求,而這時就有人想出這個奇技淫巧 :
將小圖組成一個大圖,然後在使用 js 或 css 來取得某個小圖
像這個友人說明的技術就是 Spriting。
這個技術正常應該是都會用到,這個奇技淫巧就是 :
將多個 js 檔打包成一個 js 檔。
而通常咱們會順到將這個一包 js 檔在壓縮,讓它變的小小的。
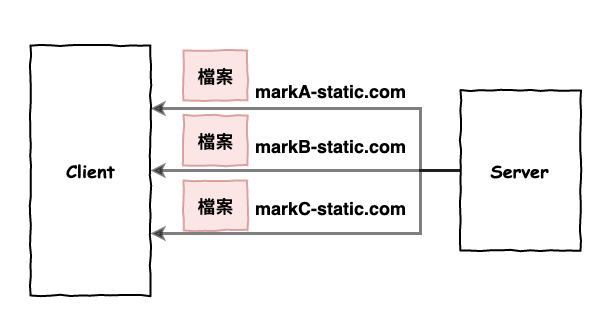
這個是專門用來處理瀏覽器 domain 限制,它主要的手法就是將一些資源放在不同的 domain 上,如下圖所示。
雖然上面用了不少奇技淫巧來處理上面這些問題,但是每一種都是應用層的處理方式,而不是個大家都遵守的『 協議 』,也就代表不是每個應用都是這樣處理的,因此後來 google 大神就開啟了 spdy 協議來嘗試解決,而這個就是 http2 的前身。
http 2 的重點就是兩個字 :
性能
它針對性能方面進行了以下幾點的加強 :
http2 解決了 http pipeline 會阻塞的問題,但這裡不是說它在 pipeline 機制上進行改善,而是直接改變整個 http 的傳輸機制,讓它可以不會阻塞。
~ 小提醒 ~
http2 沒有解決 tcp head-of-line locking 的問題。
它是如何解決的呢 ?
首先 http 2 它修改了一下封包的包裝變成如下圖 8 所示,它做兩個改變。
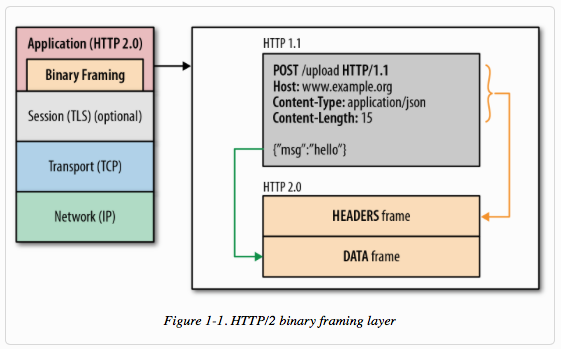
圖 8 : http 2 的封包格式 ( 圖片來源 : developers.google-Introduction to HTTP/2 )
接下來又引入了另一個重要概念『 stream 』。
stream 這東西你可以想成一條管子,然後裡面傳送的東西單位就是 frame,然後每一個 frame 都有一個 stream identifier 這欄位確認它是那個 stream。這裡要注意,它是一個邏輯的概念,而不是真的有這個 stream,它只是用 stream 來區別 request。
然後加入了『 frame 』與『 stream 』的元素以後,http2 的傳輸變成如下圖 9 所示,每一個請求都是一個 stream,而 stream 中有多個 frame,下圖每個小格子就是 frame。
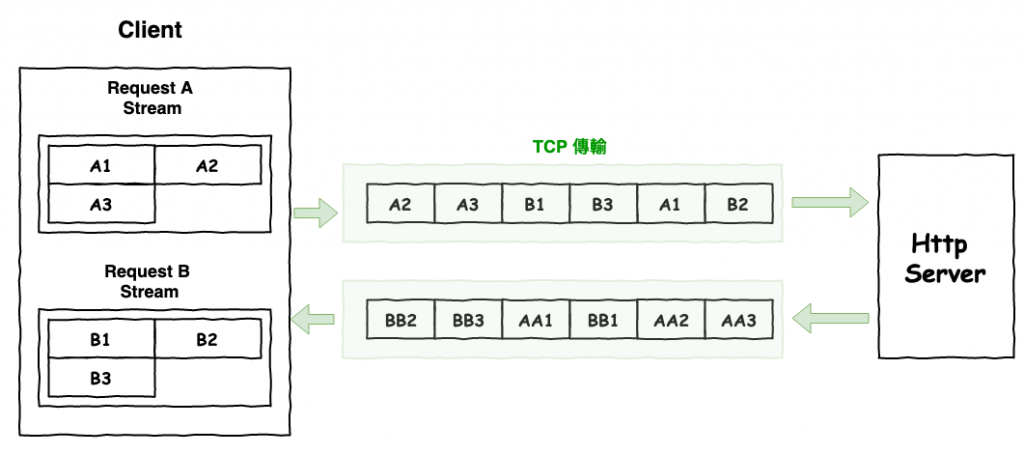
圖 9 : http2 傳輸概念 ( stream、frame )
然後與 http 1.1 相比較變成如圖 10 所示。
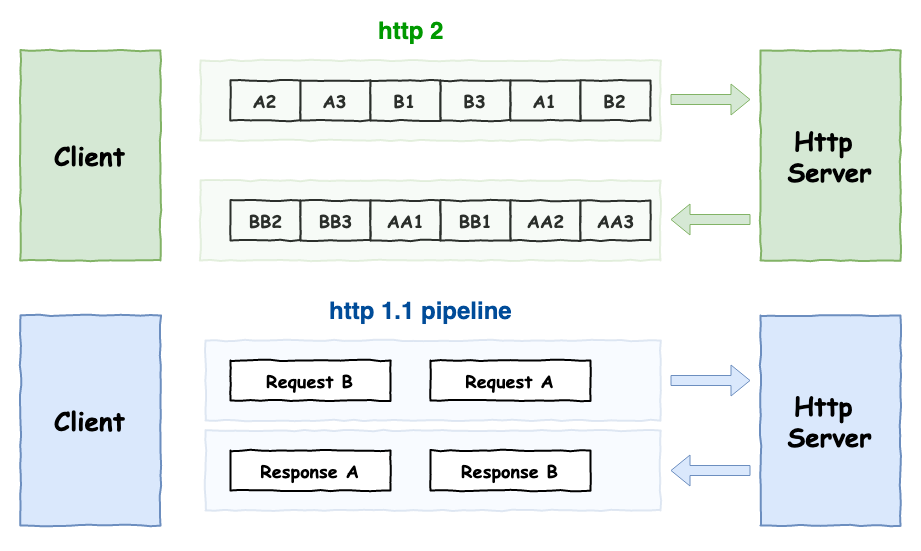
圖 10 : http2 VS http 1.1 傳輸概念。
由於每個 frame 都有說明是那一個 stream,而每一個 stream 你可以想成就是一個 http 請求,所以這時就算傳送的順序有問題,它仍然可以根據 frame 所屬的 stream 編號,重新組出某個請求的資料。
所以最後在 http2 就可以達成以下的傳輸方式,如下圖 11 所示,請求 b 不在需要等待 a 回來才能收到請求 。
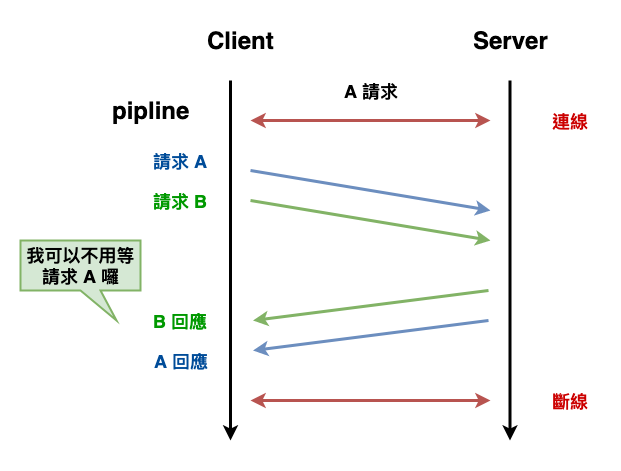
圖 11 : http2 的並行傳輸流程
然後回應時間如下所示 :
Request A : 2 sec
Request B : 1 sec
Request C : 3 sec
(這些秒數代表 server 所需花費時間)
第 0 秒時 : 發送 request GET A,B,C
第 1 秒時 : 收到 B 的回應。
第 2 秒時 : 收到 A 的回應。
第 3 秒時 : 收到 C 的回應。
共 3 秒
在 http 2 中,它有針對 header 專門進行壓縮。
不過 http 1.1 不是本來就有 gzip 壓縮了碼 ? 嗯對沒錯,它是重點在於 :
http 1.1 只是壓縮 body,沒有壓縮 header
你看看 http 1.1 header 欄位就知道,它寫的很清楚是 content 內容。
content-encoding: gzip
這個功能簡單的說它就是讓 server 端可以推送資源到瀏覽器,下圖 11 為 http 1.1 與 http 1.2 的讀網頁的差別,這圖應該就可以很清楚的知道 server push 做的事情。
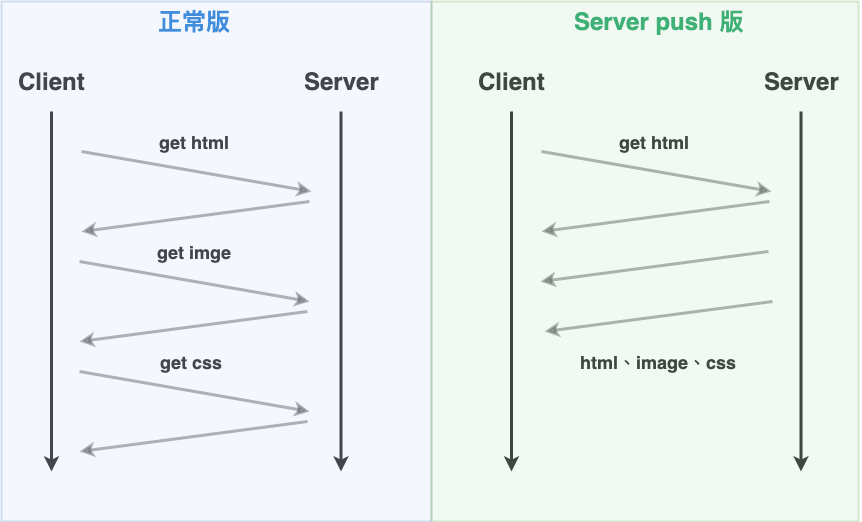
圖 12 : http 1.1 與 http 1.2 的讀網頁的差別。
這裡順到簡單的談一下 websocket 與 http2 server push 的關係,雖然它們都是可以讓 server 推東西,但是還是有點不太一樣,假設你是要推『 資料 』到前端的就用 websocket,而 server push 是用在這種 server 端主動推送『 資源、檔案 』這種情況,會更適合。
上面在 http2 有提到,它解決的是 http pipeline 的 head-of-line locking,但是它沒有辦法解決 tcp 的 head-of-line locking,所以它事實上還是會產生下面這張圖。
如圖 13 所示,當在 http2 時,已經將兩個請求分成兩個 stream 且多個 frame 後,未依順序的請 tcp 傳輸,但是如果第一個傳輸的 a1 frame 遺失或消失了,那就會導致整個 tcp 被卡住,為了等待 a1 重傳。
但是假設是在下圖 13 中的 a3 frame 遺失,那請求 b 還是會正常的處理。
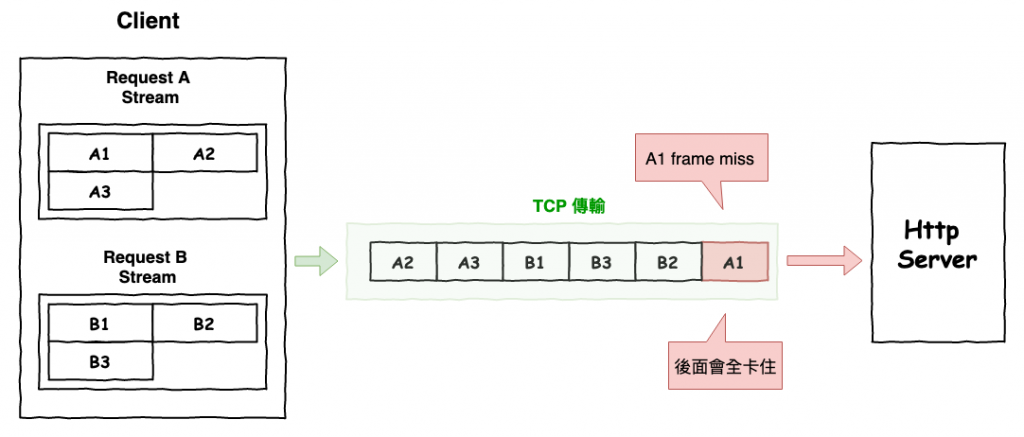
圖 13 : http2 的問題
這個問題主要是出在 tcp 的要求的可靠性,所建立出來的機制問題。它為了可靠性基本上做了兩件事情 :
『 順序 』與『 重傳 』
咱們來看一下 tcp 傳送資料的流程,如下。
假設咱們在一個 tcp 中有這些資料要傳輸,我們給它個編號為 1 至 10。
1 . 將準備要發送的資料編號 1 至 3,放至緩衝區。
2 . 幫 1 至 3 資料設定時器。
3-1 . 時間內有收到接受方的 ack ( 代表接受方有收到 1 至 3 資料 ),清除緩衝區。
3-2 . 一直沒收到 ack,則重傳。
4 . 再開始處理 4 至 7 直到全部傳完後,就送去給 http 應用層。
而這裡問題就出在這個機制,如果這時有個來插花的 http 也想用同一條 tcp 來傳輸,那這樣就會讓 tcp 產生混亂不知道如何解析這個順序,而且如果其中一個請求傳封包後,一直沒有 ack 也就會卡住所有的請求,因此 tcp 就只能這樣處理。
~ 補充知識 : tcp 滑動窗口 ~
熟悉 tcp 的友人應該知道,關於第一點只有 3 個資料 ( 1 至 3 ) 放至緩衝區這個地方,其中 3 這個數量就是滑動窗口的概念,這裡簡單的說明一下這個知識。
tcp 基本的重傳機制如下,假設 a 發送封包給 b,然後 b 會發送給 a 一個 ack ( 證明收到 ),然後這時 a 才會再發送下一個封包,但如果在一定時間內沒收到 b 的 ack ,那它就會重傳。
但這個機制非常的毛,原因在於要一直等,性能吃很大,因此 tcp 又加了這個機制下去 :
滑動窗口 ( Sliding window )
假設咱們有個請求,它的資料包序號為 1 至 8,然後下圖 6 上面部份紅色區塊窗口裡的封包(1 ~ 3)代表為可以發送的封包。
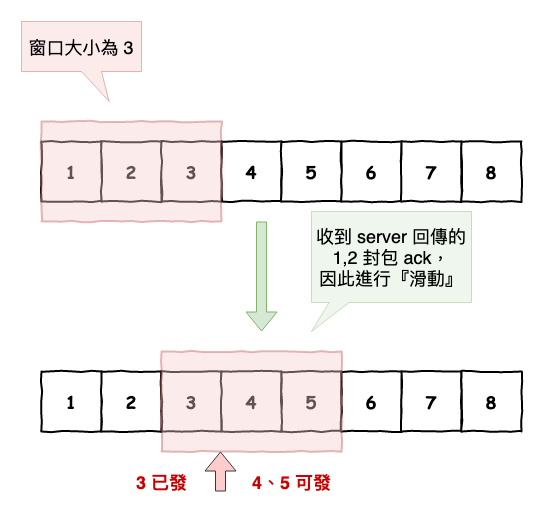
圖 14 : 滑動窗口概念
然後當發送完 1 至 3 封包後,如果接受到 1、2 封包後,窗口會往右移,變成上圖 6 下面部份,然後通常裡面會有個 point 要來判斷那些可以發送,那些還在等 ack。
由於有了這個機制的封包發送就不需要一直花時間等 ack,而可以並行的丟封包出去囉。
這裡只淺談一下滑動窗口的概念,如果真的要完整說明,那至少還要在開一篇……
HTTP3 = HTTP + QUIC ( Quick UDP Internet Connections )
由於 tcp 有上述的問題,所以就在考慮將傳輸層的 tcp 協議換掉,改成以 udp 為基礎的 quic。這裡簡單的說一下 quic、tcp、udp 都是傳輸層的東西,而 quic 是以 udp 這個不可靠的東西進行改善,讓它變成可靠性傳輸。
quic 的可靠性的重點在於 :
多傳一個包
假設一個請求有三個封包要傳輸,而這時 quic 則會傳一個特殊包,它保含其它三個的資料,也就是說就算前三個中有一個包丟失了,仍然可以用省下的三個來組合出丟失的那一個。
例如假設一個請求 quic 會準備成以下的包 :
資料包 : A,B,C,D
特殊包 : Z
它們的關係為 : A + B + C + D = Z
所以當 A 幫包丟失時,咱們可以用以下的方法反推出 A。
A = Z - B - C - D
而這個演算法就是在硬碟那很有名的 :
Raid 5 演算法
這裡就先淺淡到這。http 3 事實上還有非常多的事情還沒提到,這裡就先從 http 1.x 時代就一直被人詬病的 tcp HOL 問題拿出來看看 http 3 這它是如何解決的,之後未來有時間在詳細的寫寫 http 3 的事情。
本篇文章咱們基本上學習了 http 的整個歷史,並且也知道每一個時代的痛點與嘗試的解決方法。
最後這裡總結一下這個章節的性能優化建議 :
嘗試的將服務至升級支援為 http 2
http 2 在 2019 年這個時代,根據 W3Techs 統計,已經有大約 40+% 的網站已經有進行支援,並且提能也提升不少,可以參考此網站的比較喔。
而由於 IETF 在 2018 年時,正式的將基於 quic 協議的 http 命名為 http3,目前世界上大部份的設備應該是都還沒有完全支援,所以就先別考慮了。
可是為什麼我打開不少網站,然後開 chrome devtool networrk 看,有些請求是並行啊 ?
ajax 感覺不符合 pipeline 和 cache
好奇 Google 了一下,發現還有一個可能,分享給大大
瀏覽器會開啟多個 TCP 送資料
https://www.zhihu.com/question/36469741


 iThome鐵人賽
iThome鐵人賽